
Recipes for Next Generation Analytics
Predictive analytics applications for life and annuity products
February/March 2017Data about each of us is being collected on a minute-by-minute basis through our regular actions, such as using a credit card, sending a personal email, posting to social media, enabling location-based services on a smartphone or logging our daily exercise. While some of this data requires our permission to be collected by third parties, other elements can be collected without our permission or knowledge. 1 As a result of these new data sets and other changes, many industries, such as retail, banking and sports, are using data and advanced analytics to improve their core business operations and to better inform their strategy. Many of these efforts are focused on the consumer and how to enhance his or her experience.
Over the last few years, insurance companies have been using big data and analytics to streamline operating procedures and processes, with the goal of managing and delivering their products more efficiently. For example, application triage underwriting algorithms, which seek to identify applicants for individual life insurance for whom certain medical exams can be waived, are becoming table stakes in some life insurance distribution channels due to demands by consumers, agents and executives alike. Saving time and money, increasing placement rates and application volume, and other compelling reasons make this a logical place for many life insurance carriers to begin integrating applications of predictive analytics into their core operations.
While application triage is one example of disrupting a core business process by introducing an application of predictive analytics, it is merely the tip of the iceberg. Many new applications of predictive analytics that affect other core operations of insurance companies are being developed. This article provides a refresher on the different data sources available to insurance companies and provides a deeper dive into several innovative applications of predictive analytics for life insurance and annuity manufacturers.
Data Sources
The combination of traditional data sources and new data sources forms the foundation for advanced analytics to improve core business operations. In our current data age, it is a worthwhile exercise to take a step back and reassess what data points are being used for strategy, operations and other functions. There is a chance that some data points are not being used simply because the processes were established before the new data sets were created.
Some of the specific sources of traditional and new data to consider are:
- Traditional data sources
- Policy applications
- Paramedical exams
- Medical Information Bureau Group Inc. (MIB)
- Motor vehicle records (MVRs)
- Prescription drug databases
- Traditional data sources that are now easier to obtain quickly, inexpensively and in a digital format
- Property records—ownership, tax appraisal and so on
- Genealogy records—births and death
- Marriage licenses and divorce decrees
- Criminal records, court dockets, jail inmate records
- Voter registration
- Bankruptcy records
- New data sources
- Third-party marketing databases
- Electronic health records (EHRs)
- Biometric data from wearable devices
- Social networking sites
- Behavioral and lifestyle data
Given that the sheer number of data points and their potential correlations can be overwhelming, there are standardized and proven procedures that can help. For example, a univariate review can test which variables are statistically significant with the proposed dependent variable. This helps to narrow down the number of variables to those that reflect the most predictive power, among other factors like reputational risk, legal impact, data availability in the future and changes to vendor relationships.
Often, the data utilized by predictive analytics includes health, behavioral and lifestyle information that can be highly sensitive and closely regulated. In the United States, the Fair Credit Reporting Act and the Health Insurance Portability and Accountability Act (HIPAA) primarily apply, along with state privacy laws and other rules.2 These should be considered, along with the intended business purpose, when deciding what data should be used.
Insurance Functions Affected
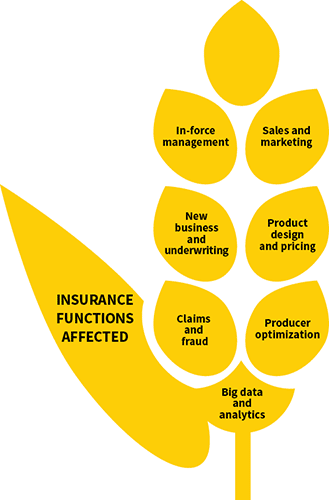 While big data and analytics may have only permeated one or more functions of many insurance companies, it is likely that they will have an impact on the remaining functions in the near term. A helpful mindset to take is that additional data and analytics can help enhance current processes and do not necessarily need to replace the current processes entirely. This incremental mindset is more practical and can help functional leaders maintain current service level agreements while improving efficiency, effectiveness, cost and/or timeliness of that business function. This incremental approach helps the company/function progress toward transformational change in the long term. There are tools and accelerators that insurance companies can use from third-party vendors to promptly tap into data sets and leverage off-the-shelf models.
While big data and analytics may have only permeated one or more functions of many insurance companies, it is likely that they will have an impact on the remaining functions in the near term. A helpful mindset to take is that additional data and analytics can help enhance current processes and do not necessarily need to replace the current processes entirely. This incremental mindset is more practical and can help functional leaders maintain current service level agreements while improving efficiency, effectiveness, cost and/or timeliness of that business function. This incremental approach helps the company/function progress toward transformational change in the long term. There are tools and accelerators that insurance companies can use from third-party vendors to promptly tap into data sets and leverage off-the-shelf models.
Example 1: Agent and Policyholder Matching
In addition to enhancing underwriting and retention operations, big data and analytics can be used to improve the relationship between insurance company agents and policyholders. Predictive algorithms can be developed to identify characteristics of agents and policyholders that have contributed to effective relationships in the past. These characteristics then can be applied to optimize the future matching of agents and new policyholders. By identifying the characteristics that have best aligned agents and policyholders, insurance companies can improve agent retention and productivity while improving the policyholder experience and retention.
Example 2: Enhanced Assumption-Setting
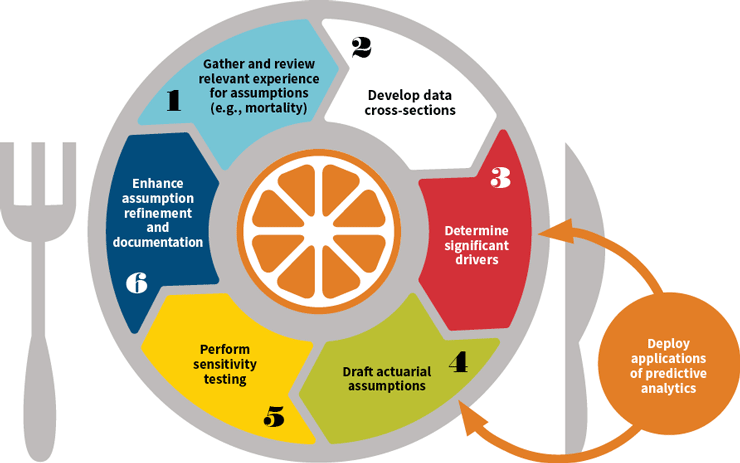
Big data and analytics can enhance the traditional actuarial assumption-setting process to provide deeper insights. Third-party marketing data sets exist with several thousand data fields on most individuals in the United States. Those data fields can be sent through an algorithm to score each individual and create an estimate of future mortality for each individual. That scoring distribution can be appended to traditional assumptions to make the final result more accurate and granular. This is helpful when internal experience upon which to base assumptions is not credible enough.(See Figure 1).
Figure 1: Enhanced Assumption-Setting
Example 3: Policyholder Wellness Programs
Big data and analytics are not limited to process improvements. They also can be extended to the products that insurance companies sell. Big data and analytics don’t simply change how insurance companies operate internally or go to market—they also can improve what they offer to the market.
For example, wellness programs are becoming more commonplace in today’s workplace. These programs have a component of social good, as they often are win-win programs for policyholders and insurance companies. They instill a sense of competition and offer opportunities to interact with other participants. These types of wellness programs are being embedded within health or life insurance products. A policyholder wellness program by an insurance company could include offering personalized health challenges to participants who earn rewards for completing those challenges. The rewards could include premium discounts, free health checkups, gift cards to retail stores and other rewards. These programs have the potential to generate benefits for both the policyholders and the insurance companies. Benefits include:
- Increased quantity and quality of policyholder interactions, improving the communication process.
- Improved policyholder customer experience from the health benefits stimulated by the programs, helping policyholders achieve improved length and quality of life.
- Generating financial benefits for the insurer in the form of reduced and/or deferred claims and increased premium revenue, because of the increased length and quality of life.
- The life insurer may appeal to a more health-conscious segment of the population by offering the program, effectively generating “favorable selection” benefits to the company’s mortality and morbidity risks.
- The products can create a richer data set for insurance companies, which can be used for future predictive modeling initiatives.
Conclusion
Agent and policyholder matching, enhanced assumption- setting and policyholder wellness programs: These are three specific examples of ways that insurance companies are utilizing new sources of data and advanced analytics in their core business operations. The opportunity set spans the entire insurance lifecycle, from marketing to new business, to reinsurance, to inforce management, to claims. Although this may seem daunting, the changes are doable if they are broken into bite-sized chunks. Internal and external data sets should be reviewed with fresh eyes to see if they can augment traditional processes. A variety of advanced and predictive statistical techniques can then be applied to the data—from generalized linear models, to classification/tree-based modeling, to artificial intelligence modeling. This way, companies can begin to translate everyday information into actionable insights by embedding analytics across the organization’s strategy, operations and systems, and by building analytics into core organizational areas, including customer, supply chain, finance, risk and workforce.
operations for life insurance and annuity manufacturers.
References:
- 1. Ferris, Andy, David Moore, Nathan Pohle, and Priyanka Srivastava. “Big Data: What Is It, How Is It Collected, and How Might Life Insurers Use It?” The Actuary, December 2013/January 2014, 26–32. ↩
- 2. Clark, Matthew, Andy Ferris, Nathan Pohle, Priyanka Srivastava, and Jeff Huddleston. “Navigating a New Landscape.” Best’s Review, September 2014, 34–32. ↩